This morning I walked out of the bedroom to make my morning coffee and was greeted with a tech support problem. My wife had been up for a while already, and said something was wrong with the network. Coffee in hand, I opened the laptop and was greeted with a warning that I had no Internet access.
As I started to pull up my usual diagnostics pages, I found that DNS requests were timing out in some cases and getting through in other cases, but in the latter case the web page loads were eventually timing out anyway. I logged into my first hop gateway/firewall and found it rather slow to respond to keystrokes, and it took several minutes just to display the last 1000 syslog messages. Other VMs on my network behaved the same way.
Perplexed, I went to my office at the other end of the house and sat down to investigate further. Nothing looked awry: no CPUs were loaded on any hosts or VMs I could access, no kernel panics were to be seen, and despite the fact that I couldn't load my LibreNMS dashboard properly, it had not alerted me via OpsGenie, nor had my external monitoring from StatusCake chirped. So it seemed like all the core elements of my network were fine.
Then the problem just disappeared. Everything just went back to normal and worked fine. No timeouts, no unresponsive servers, just normal operation.
I don't know about you, but when a problem like this just goes away, I don't just shrug my shoulders and move on, I get all Mark Watney about it:
I checked my switch port statistics. It had been days since anything had flapped, and I knew that was due to a reboot I had initiated. There were a couple of ports with non-zero counters - the VM server hosting my first hop firewall VM, and one of my wifi APs, but nothing that seemed to be outrageous given the time the stats were last cleared (weeks ago). I cleared them again with the plan to come back later and see how fast they were clocking up. I proceeded to go through the last 24 hours of absolutely everything LibreNMS could show me across all hosts: CPU, memory, disk space, network traffic, errors, even temperature. None of them seemed to be particularly problematic.
My sciencing seemed like a failure. In desperation I reached for another tool which I had only just got fully working again after migrating my management VM to a new host a couple of days earlier: Smokeping. Eventually, as I worked down the list of hosts, I came to my first wifi AP, and found this:
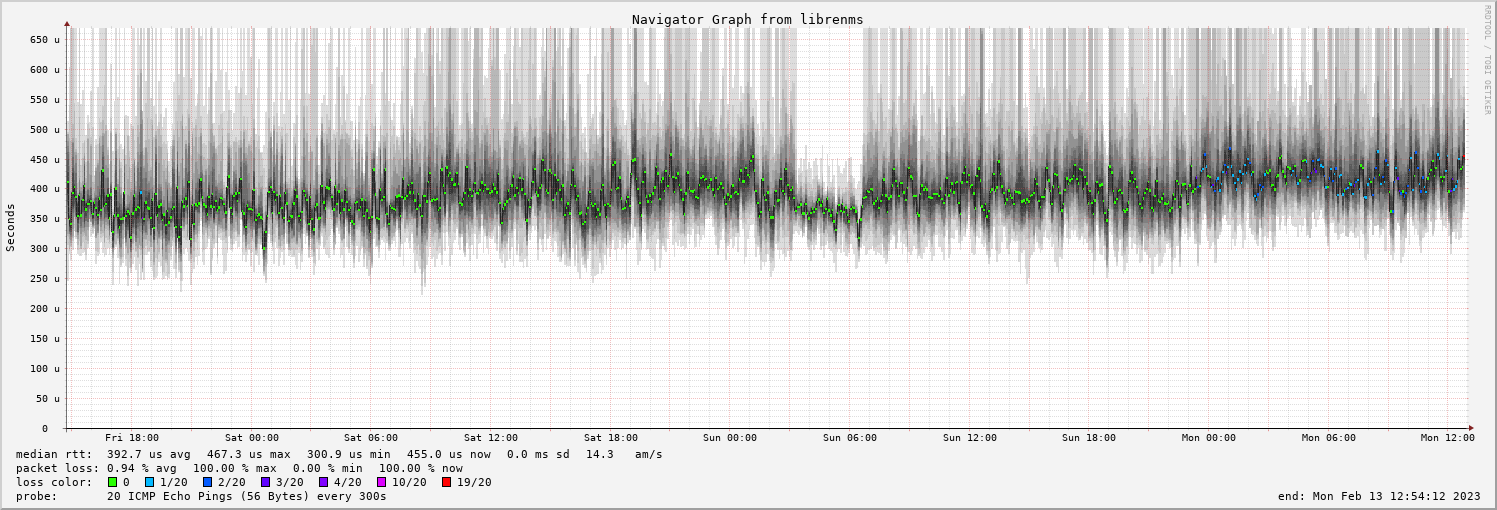 Smokeping graph of my wifi AP
Smokeping graph of my wifi AP
At first glance it doesn't seem too bad, but somewhere after 23:00 last night, there's a subtle shift in colour in that central data point from green to blue. The errors weren't too bad from the switch's perspective, but as far as round trips were concerned the AP had started dropping pings. I had a bad network cable between the AP and the switch, or the AP itself was bad.
This explained all of the symptoms: I was getting packet loss on wifi, so DNS, HTTPS, and ssh to my servers was slow, but as far as the rest of the network was concerned, everything was fine. The problem went away because when I went into the office my laptop roamed from the lounge AP onto my office AP, which was working fine. I powered down the lounge AP and proceeded with my day.
I came back tonight to fully diagnose the problem, and sure enough, my (relatively simple) cable tester showed pin 3 on the patch cable at the switch end was faulty. A quick replacement, and we're back in business!
The morals of the story:
- there's a lot to be said for simple old tools that just work away in the background checking things,
- ICMP echos are still a great diagnostic tool, and
- an error count doesn't have to be very high to have a dramatic effect on network performance.