NTP: a behind-the-scenes protocol
As I've mentioned before, Network Time Protocol is one of those oft-ignored-but-nonetheless-essential subsystems which is largely unknown, except to a select few. Those who know it well generally fall into the following categories:
- time geeks who work on protocol standardisation and implementation,
- enthusiasts who tinker with GPS receivers or run servers in the NTP pool, or
- sysadmins who have dealt with the consequences of inaccurate time in operational systems. (I fall mostly into this third category, with some brief forays into the others.)
One of the consequences of NTP's low profile is that many important best practices aren't widely known and implemented, and in some cases, myths are perpetuated.
Fortunately, Ubuntu & other major Linux distributions come out of the box with a best-practice-informed NTP configuration which works pretty well. So sometimes taking a hands-off approach to NTP is justified, because it mostly "just works" without any special care and attention. However, some environments require tuning the NTP configuration to meet operational requirements.
When best practices require more
One such environment is Canonical's managed OpenStack service, BootStack. A primary service provided in BootStack is the distributed storage system, Ceph. Ceph's distributed architecture requires the system time on all nodes to be synchronised to within 50 milliseconds of each other. Ordinarily NTP has no problem achieving synchronisation an order of magnitude better than this, but some of our customers run their private clouds in far-flung parts of the world, where reliable Internet bandwidth is limited, and high-quality local time sources are not available. This has sometimes resulted in time offsets larger than Ceph will tolerate.
A technique for dealing with this problem is to select several local hosts to act as a service stratum between the global NTP pool and the other hosts in the environment. The Juju ntp charms have supported this configuration for some time, and historically in BootStack we've achieved this by configuring two NTP services: one containing the manually-selected service stratum hosts, and one for all the remaining hosts.
We select hosts for the service stratum using a combination of the following factors:
- Reasonable upstream Internet connectivity is needed. It doesn't have to be perfect - NTP can achieve less than 5 milliseconds offset over an ADSL line, and most of our customer private clouds have better than that.
- Bare metal systems are preferred over VMs (but the latter are still workable). Containers are not viable as NTP servers because the system clock is not virtualised; time synchronisation for containers should be provided by their host.
- There should be no "choke points" in the NTP strata - these are bad for both accuracy and availability. A minimum of 3 (but preferably 4-6) servers should be included in each stratum, and these should point to a similar number of higher-stratum NTP servers.
- Because consistent time for Ceph is our primary goal, the Ceph hosts themselves should be clients rather than part of the service stratum, so that they get a consistent set of servers offering reliable response at local LAN latencies.
A manual service stratum deployment
Here's a diagram depicting what a typical NTP deployment with a manual service stratum might look like:
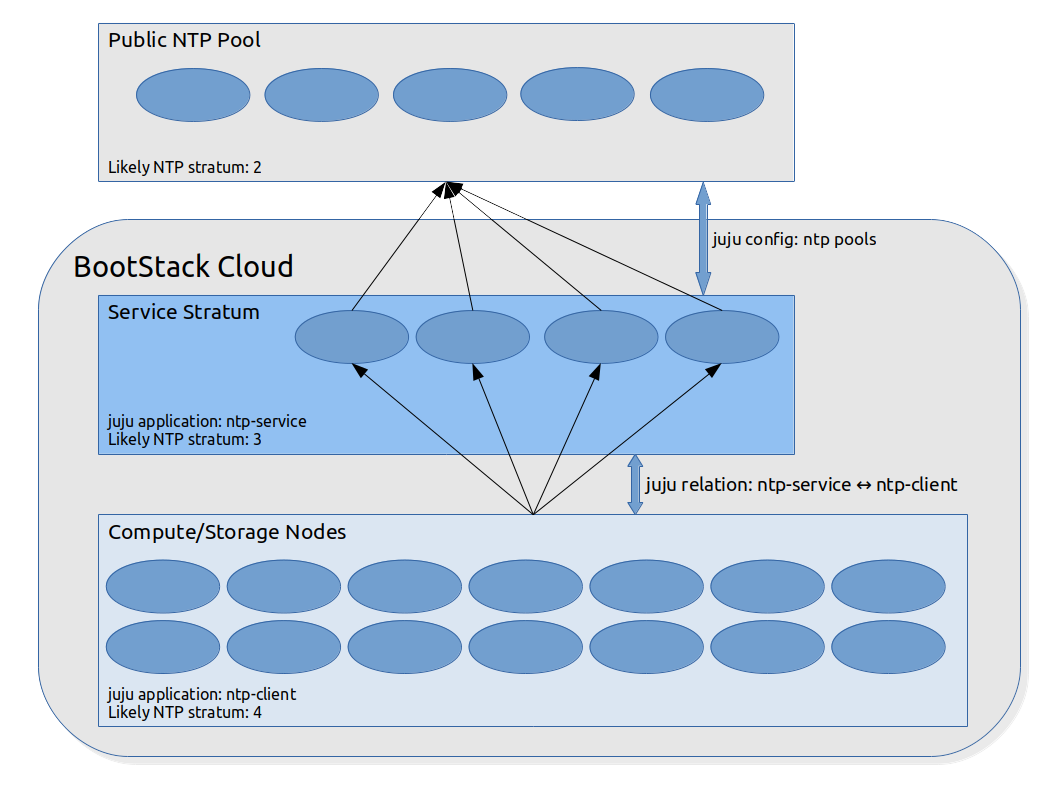
To deploy this in an existing BootStack environment, the sequence of commands might look something like this (application names are examples only):
# Create the two ntp applications:
$ juju deploy cs:ntp ntp-service
# ntp-service will use the default pools configuration
$ juju deploy cs:ntp ntp-client
$ juju add-relation ntp-service:ntpmaster ntp-client:master
# ntp-client uses ntp-service as its upstream stratum
# Deploy them to the cloud nodes:
$ juju add-relation infra-node ntp-service
# deploys ntp-service to the existing infra-node service
$ juju add-relation compute-node ntp-client
# deploys ntp-client to the existing compute-node service
Updating the ntp charm
It's been my desire for some time to see this process made easier, more accurate, and less manual. Our customers come to us wanting their private clouds to "just work", and we can't expect them to provide the ideal environment for Ceph.
One of my co-workers, Stuart Bishop, started me thinking with this quote:
"[O]ne of the original goals of charms [was to] encode best practice so software can be deployed by non-experts."
That seemed like a worthy goal, so I set out to update the ntp charm to automate the service stratum host selection process.
Design criteria
My goals for this update to the charm were to:
- provide a stable NTP service for the local cloud and avoid constantly changing upstream servers,
- ensure that we don't impact the NTP pool adversely, even if the charm is widely deployed to very large environments,
- provide useful feedback in juju status which is sufficient to explain its choices,
- use only functionality available in stock Ubuntu, Juju, and charm helpers, and
- improve testability of the charm code and increase test suite coverage.
What it does
- This functionality is enabled using the auto_peers configuration option; this option was previously deprecated, because it could be better achieved through juju relations.
- On initial configuration of auto_peers, each host tests its latency to the configured time sources.
- The charm inspects the machine type and the software running on the system, using this knowledge to reduce the likelihood of a Ceph, Swift, or Nova compute host being selected, and to increase the likelihood that bare metal hosts are used. (This usually means that the Neutron gateways and infrastructure/monitoring hosts are more likely to be selected.)
- The above factors are then combined into an overall suitability score for the host. Each host compares its score to the other hosts in the same juju service to determine whether it should be part of the service stratum.
- The results of the scoring process are used to provide feedback in the charm status message, visible in the output of juju status.
- if the charm detects that it's running in a container, it sets the charm state to blocked and adds a status message indicating that NTP should be configured on the host rather than in the container.
- The charm makes every effort to restrict load on the configured NTP servers by testing connectivity a maximum of once per day if configuration changes are made, or once a month if running from the update-status hook.
All this means that you can deploy a single ntp charm across a large number of OpenStack hosts, and be confident that the most appropriate hosts will be selected as the NTP service stratum.
Here's a diagram showing the resulting architecture:
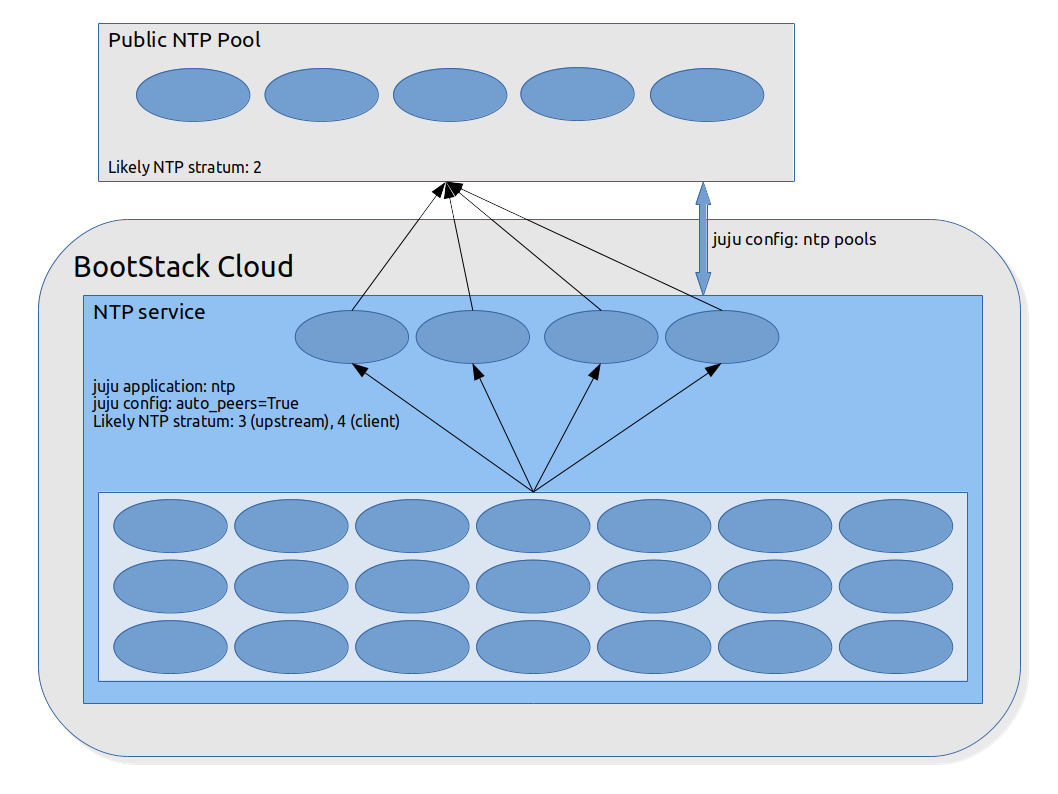
How it works
- The new code uses ntpdate in test mode to test the latency to each configured source. This results in a delay in seconds for each IP address responding to the configured DNS name.
- The delays for responses are combined using a root mean square, then converted to a score using the negative of the natural logarithm, so that delays approaching zero result in a higher score, and larger delays result in a lower score.
- The scores for all host names are added together. If the charm is running on a bare metal machine, the overall score given a 25% increase in weighting. If the charm is running in a VM, no weight adjustment is made. If the charm is running in a container, the above scoring is skipped entirely and the weighting is set to zero.
- The weight is then reduced by between 10% and 25% based on the presence of the following running processes: ceph, ceph-osd, nova-compute, or swift.
- Each unit sends its calculated scores to its peer units on the peer relation. When the peer relation is updated, each unit calculates its position in the overall scoring results, and determines whether it is in the top 6 hosts (by default - this value is tunable). If so, it updates /etc/ntp.conf to use the configured NTP servers and flags itself as connecting to the upstream stratum. If the host is not in the top 6, it configures those 6 hosts as its own servers and flags itself as a client.
How to use it
This updated ntp charm has been tested successfully with production customer workloads. It's available now in the charm store. Those interested in the details of the code change can review the merge proposal - if you'd like to test and comment on your experiences with this feature, that would be the best place to do so.
Here's how to deploy it:
# Create a single ntp service:
$ juju deploy --channel=candidate cs:ntp ntp
# ntp service still uses default pools configuration
$ juju config ntp auto_peers=true
# Deploy to existing nodes:
$ juju add-relation infra-node ntp
$ juju add-relation compute-node ntp
You can see an abbreviated example of the juju status output for the above deployment at http://pastebin.ubuntu.com/25901069/.
Related posts
- AWS microsecond-accurate time: a second look
- VM timekeeping: Using the PTP Hardware Clock on KVM
- The Little Network That Could: Time Infrastructure
- AWS microsecond-accurate time: a first look
- What’s the time, Mister Cloud? An introduction to and experimental comparison of time synchronisation in AWS and Azure, part 1