Background
In my recent posts I've been focusing on time synchronisation in virtual machines in public clouds. In my upcoming posts I'm going to cover how to apply the same techniques to improve time sync on generic KVM guests. Before we dive into that, I want to give an overview of the infrastructure I use to provide NTP for my network (a.k.a. The Little Network That Could).
I was recently privileged to attend IETF 119 in Brisbane, where I met Marco Davids and we compared notes on NTP operations. My network's design emphasis on low cost, low power, and low noise means that the components used are quite different from those Marco and his colleagues used for the SIDN Labs time.nl service, but I realised that the topology design and measurement strategy were not very different.
In my network I use NTP for time sync between the stratum 1 devices and other hosts, and virtual machines for the pool hosts. There are multiple stratum 1 servers, and multiple public-facing pool machines on different hardware. Here's a diagram showing the overall structure with the IPs of the public hosts:
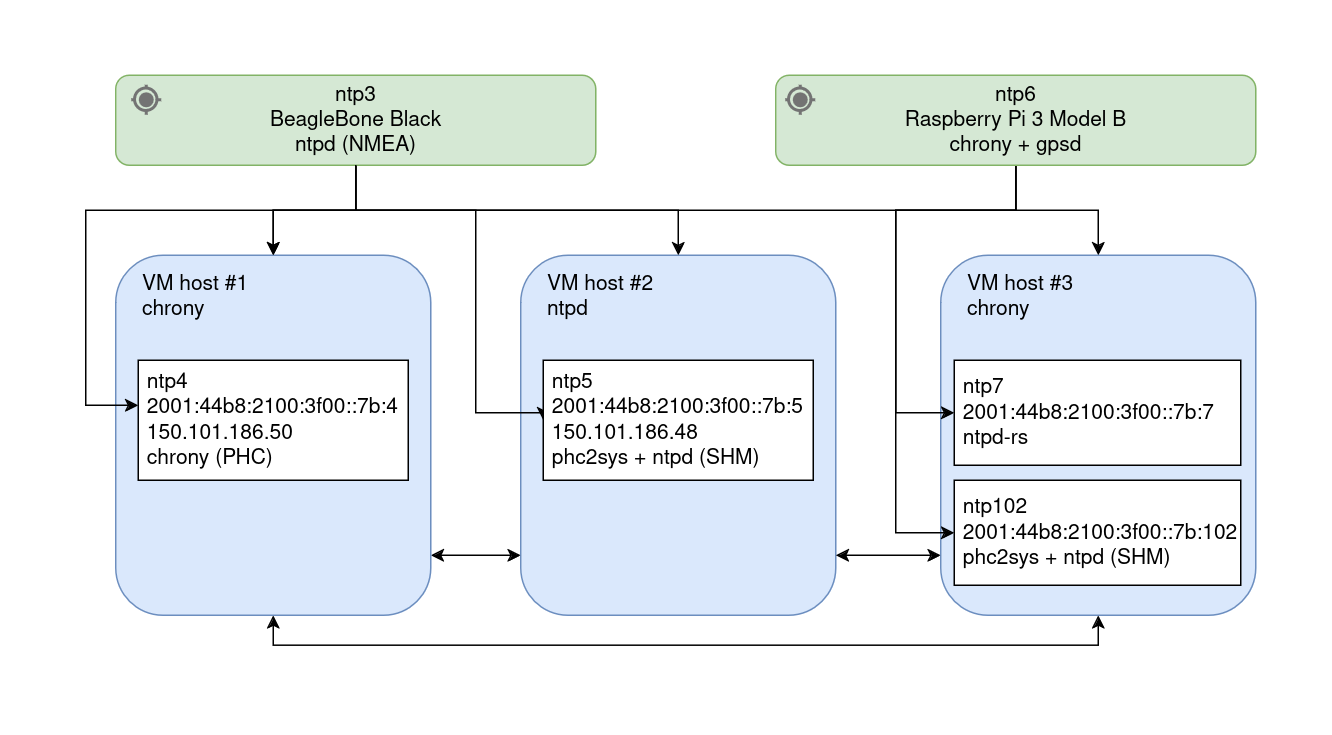
NTP root servers
The main stratum 1 NTP sources on my network are two small embedded Linux systems with GPS receivers. The first is a BeagleBone Black with a custom GPS board based on a uBlox chipset, running ntpd using the NMEA driver to provide both GPS time and a PPS (pulse-per-second) signal.
The second stratum 1 host is a Raspberry Pi 3 Model B with another custom GPS board (also based on a uBlox chipset) commissioned by "Honest" Rob (xrobau) Thomas. It runs chronyd and gpsd to obtain the GPS time and PPS signal.
Both stratum 1 hosts run Debian GNU/Linux. They are only accessible internally, to prevent any possibility of network-based DDoS attacks affecting the time service. (Although, my Internet connection would likely crumble under DDoS long before the time servers.) External backup stratum 1 servers are configured to allow for the possibility of a GPS outage taking out their sources (although the PPS signals would likely keep them ticking reliably).
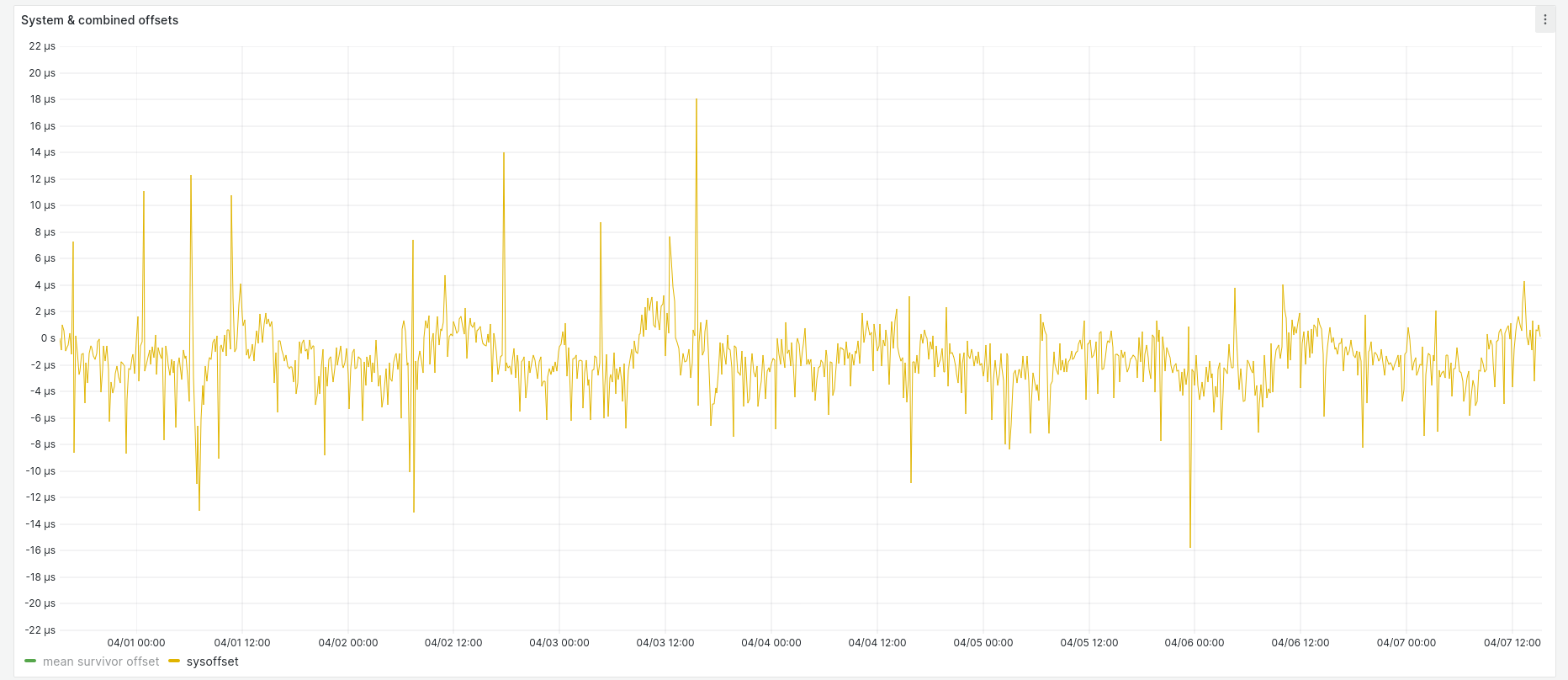
The BeagleBone Black was my first stratum 1 server. It's pretty low-end hardware (1 GHz CPU, 512 MB RAM), but still tracks within ± 20 microseconds of its GPS source:
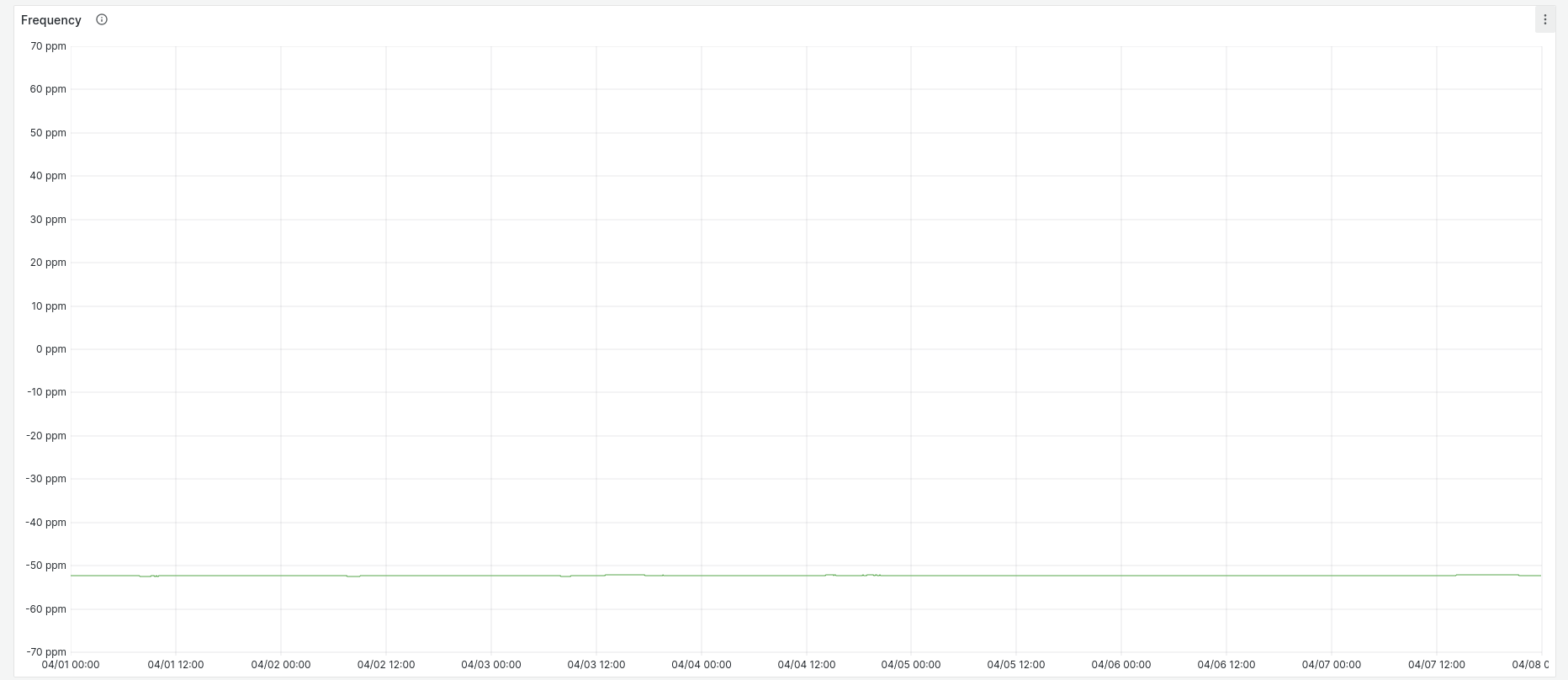
Looking at frequency error over the same time period, it's pretty stable:
Although if we remove the graph constraint to always include zero on the Y axis, we can see that there is periodic variation:
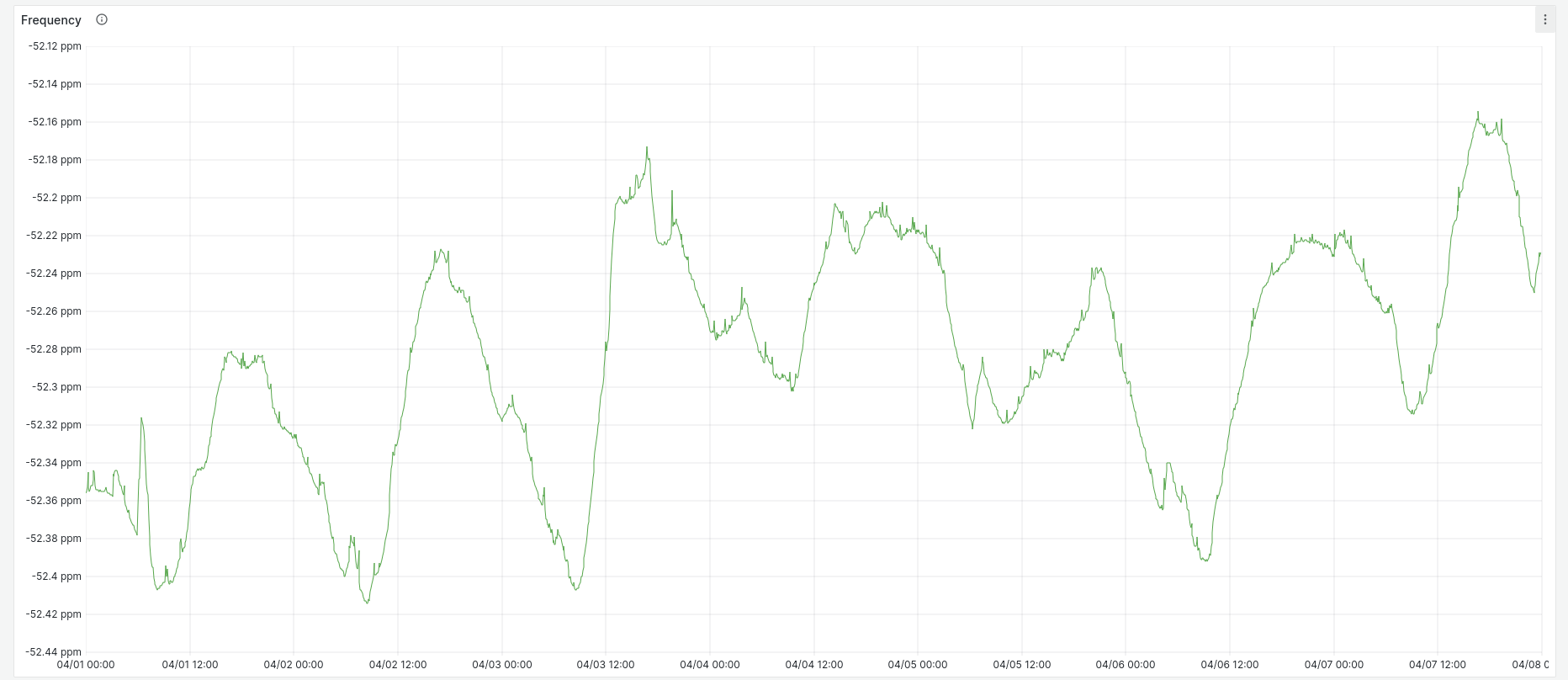
The system is not in a temperature-controlled environment, and the peaks and troughs of frequency closely match those of my weather station's indoor temperature readings over the same time period:

If you'd like to dig into the data, here's a Grafana snapshot for this system over a one-week period: https://snapshots.raintank.io/dashboard/snapshot/V8lcRJEY1jhHe1h8EqQSEalkzEW9WG0O
Bare metal VM hosts
The stratum 1 servers are used as the sources for my bare metal hosts, all of which run the KVM hypervisor. These hosts also reference each other, with orphan mode enabled so that in the event of the stratum 1 sources being unavailable, a leader will be elected from amongst them. The VM hosts run chrony as their NTP service, on Ubuntu Linux, and host all of my NTP pool servers.
Here are some stats for the system marked as VM host #3 above. It hosts the ntp7 and ntp102 pool VMs. It's running on an Intel Pentium J3710, an older quad-core CPU with a maximum clock rate of 2.6 GHz.
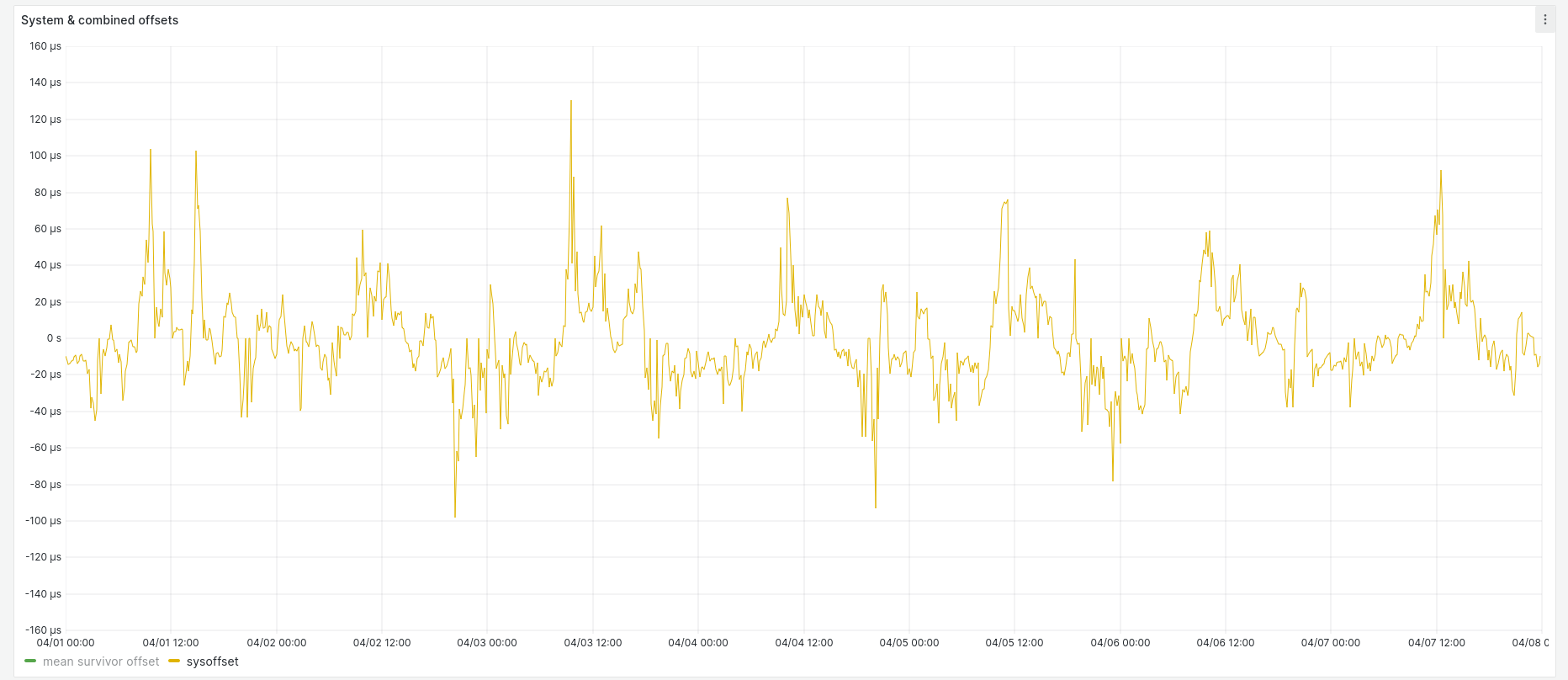
System offset ranges between ± 140 µs:
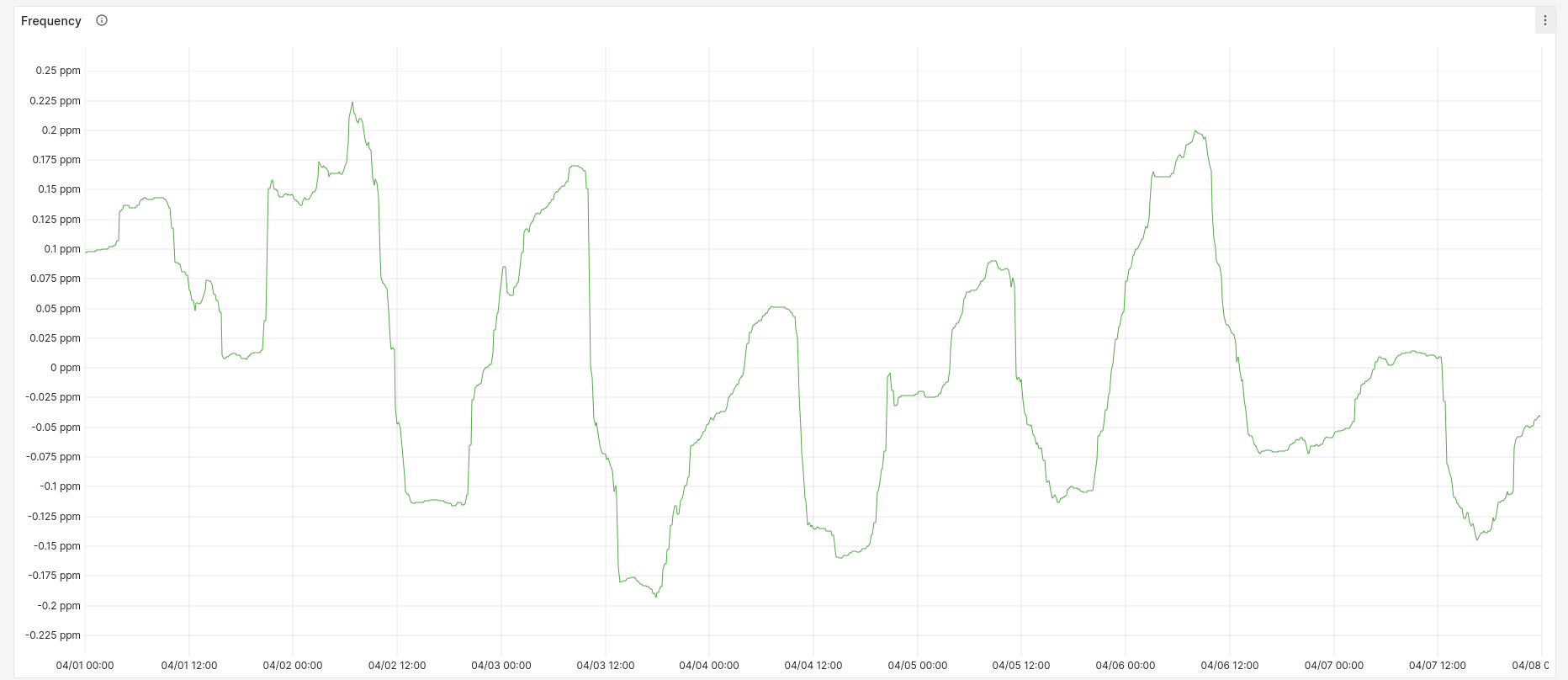
Frequency error has a slightly wider range of values than the BeagleBone, with the same regular pattern based on temperature:
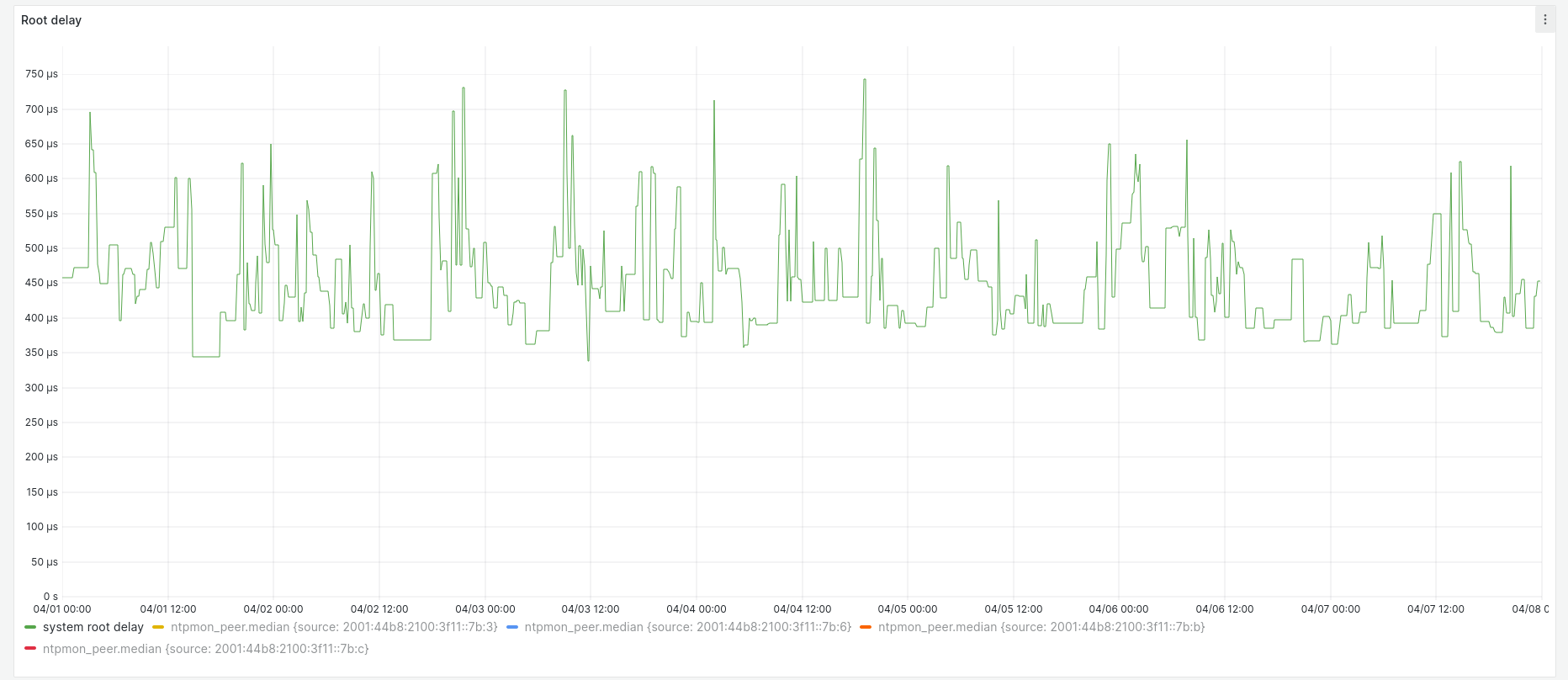
Root delay ranges between 350 µs and 750 µs. The VM hosts are in the same subnet as the stratum 1 servers, connected by 1 Gbps Ethernet (although the BeagleBone is only 100 Mbps):
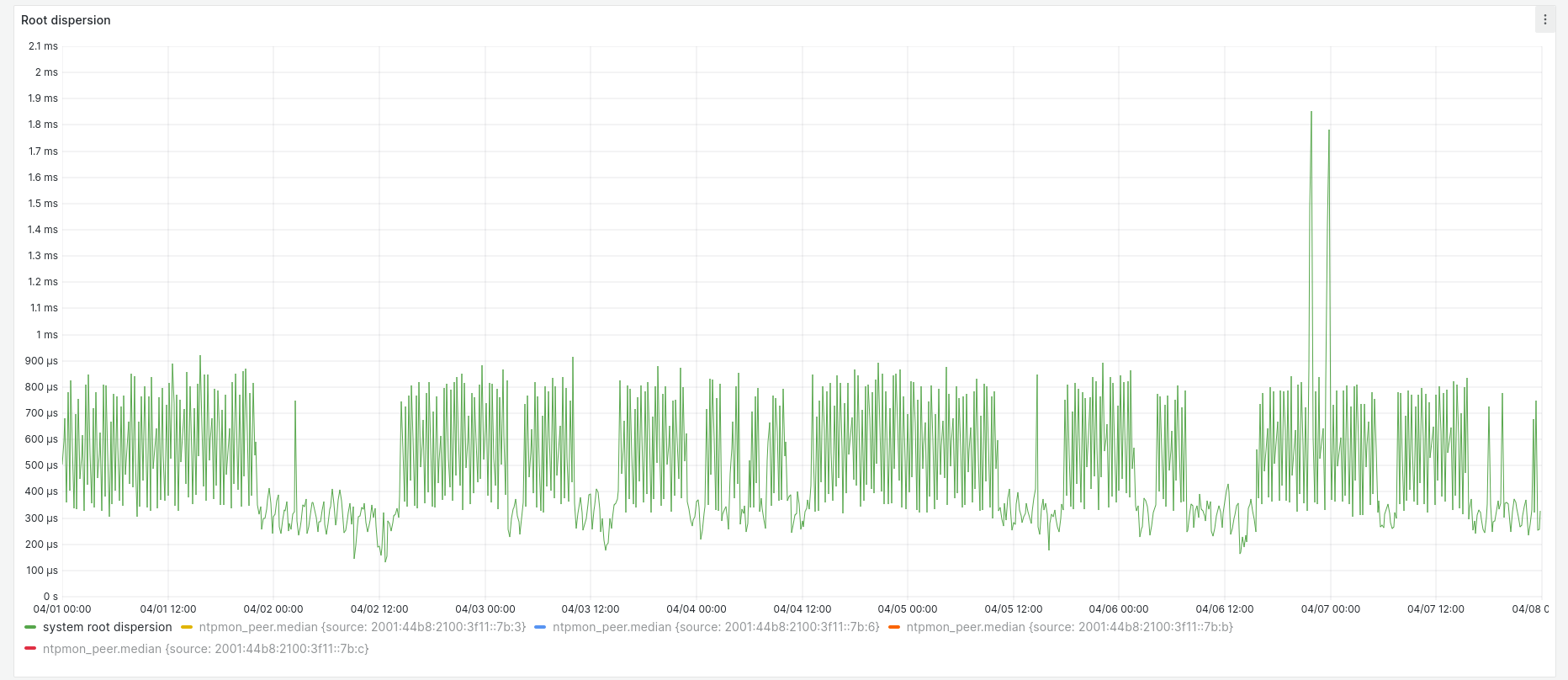
Root dispersion peaks at around 2 milliseconds:
Here's a Grafana snapshot of this host over a one-week period: https://snapshots.raintank.io/dashboard/snapshot/xHdgapqImIxKOH36x9dk2rkA6UjPYrwg
NTP pool VMs
At the moment I have four hosts in the public NTP pool. Two are dual-stacked, and two are IPv6-only. My public IPv4 address space is only a /29 and is 100% utilised, so all future pool hosts will be IPv6-only.
The KVM hypervisor provides a PTP hardware clock (PHC) device which needs no special setup other than loading the ptp_kvm driver in the guest. All of the pool VMs are configured to poll this driver (apart from ntp7, because ntpd-rs doesn't yet support the PHC device). The pool VMs also poll the stratum 1 servers directly, but as long as the PHC device is functional, it stays selected as the sync peer.
Here's a snapshot of the pool host ntp102 over a one-week period: https://snapshots.raintank.io/dashboard/snapshot/FrJ0HQJ6lpBtfjezDHwbwKVauChd9TMN
The offset stays within ± 80 µs of the host:
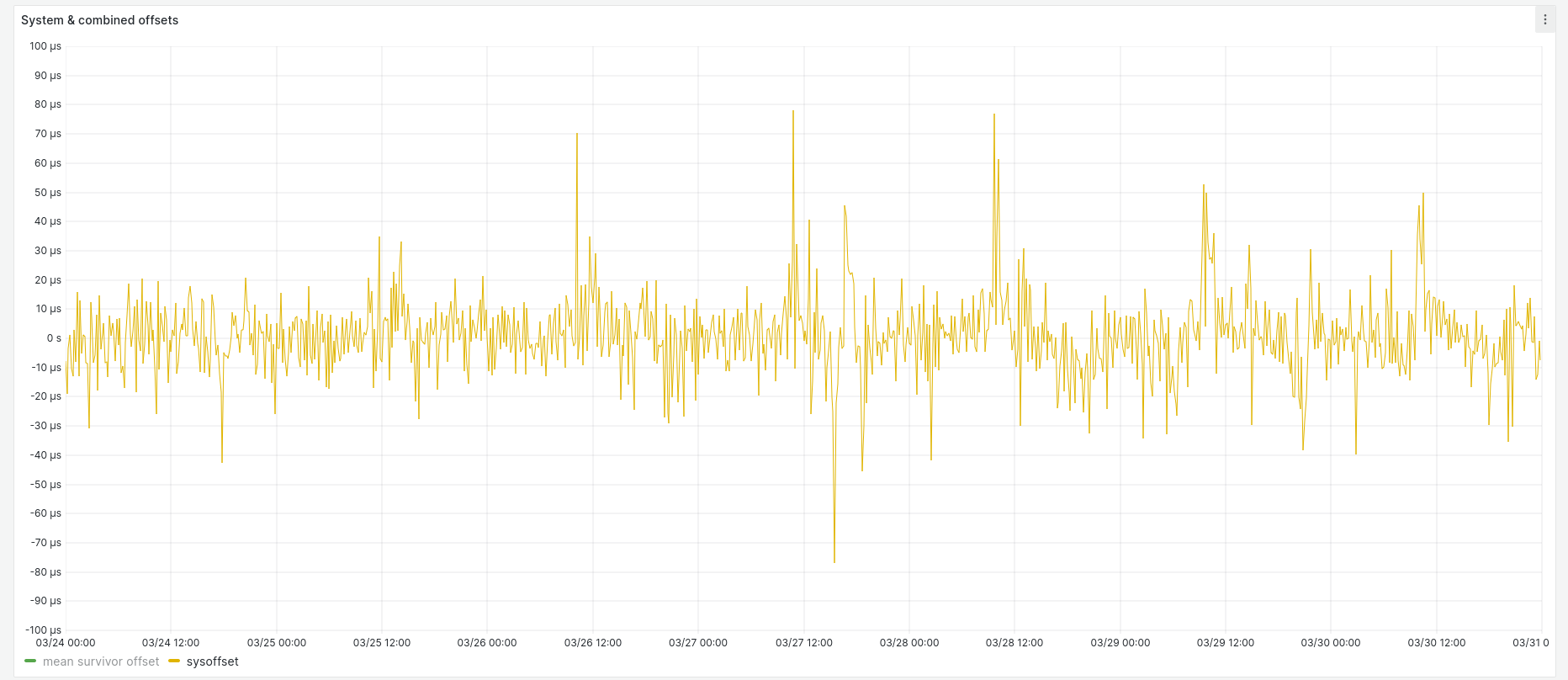
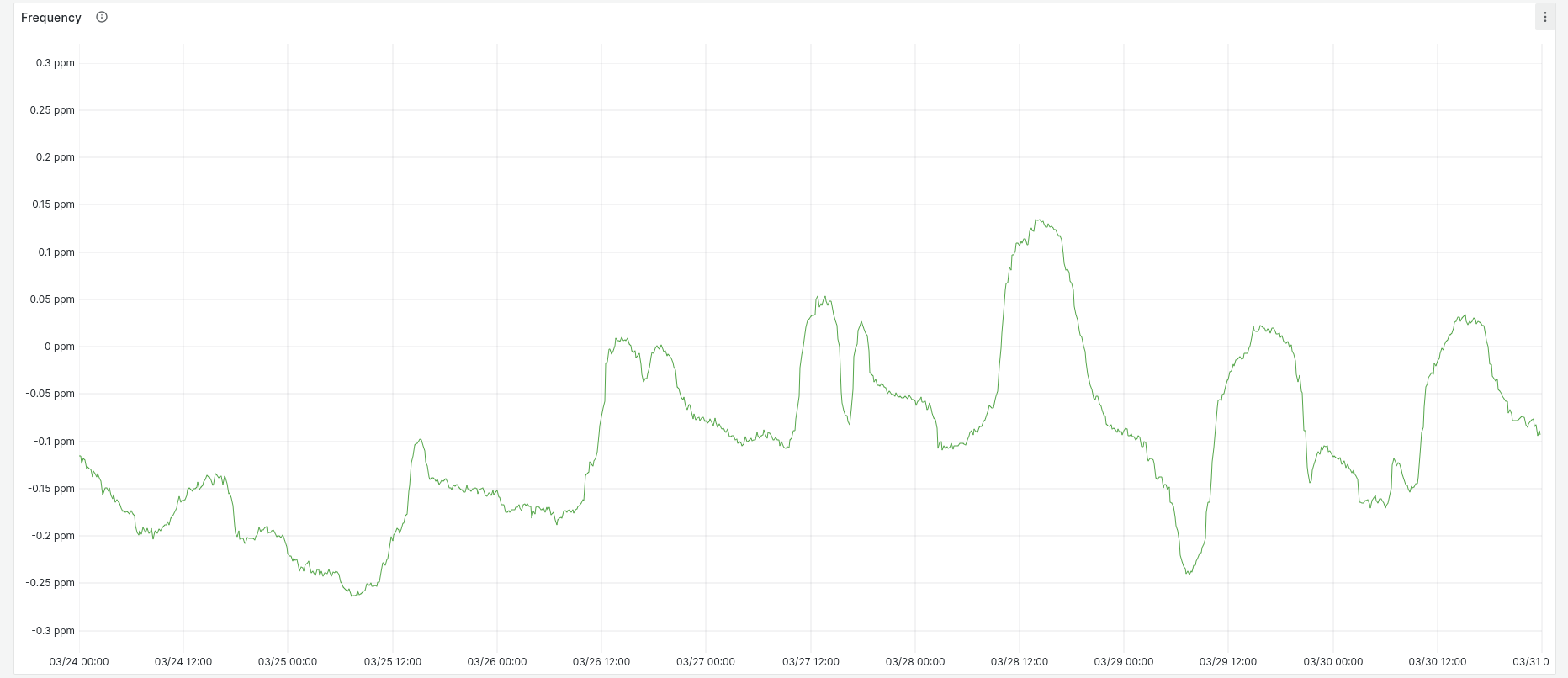
Because the VM tracks the host quite closely, we can see the same temperature-related variance in system frequency as the host (although they're not identical):
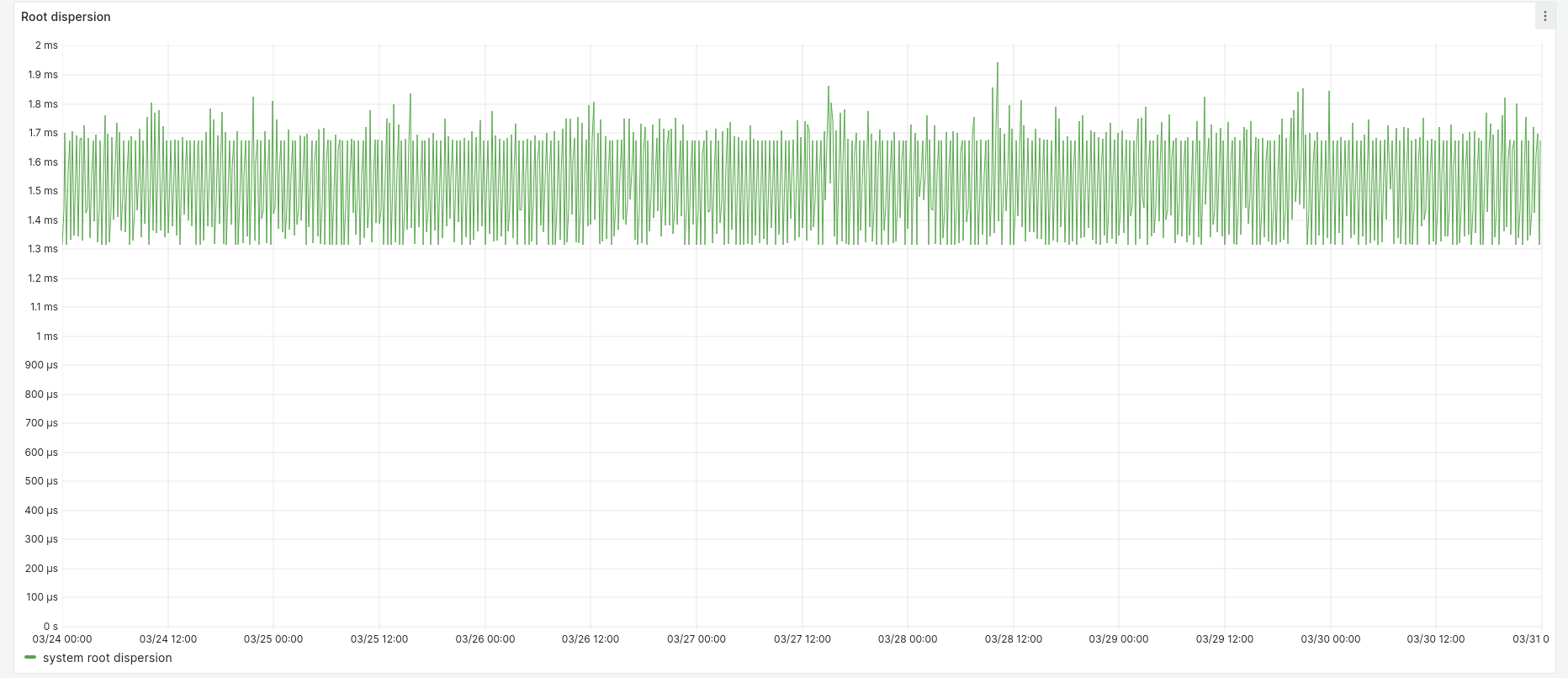
And the root dispersion is in a band between 1.3 and 2.0 ms:
(Root delay is always zero with the ntpd SHM driver, so it's not shown here.)
Monitoring
The Grafana dashboards linked above are created by my script NTPmon to gather summary and per-source NTP statistics and forward them to my InfluxDB metrics store via telegraf. I recently switched from Prometheus to InfluxDB because the latter is more well-suited to NTP monitoring, due to the fact that it records the timestamp for each measurement in nanosecond resolution at the point of collection rather than on the metrics server. This is important because I want to track what each NTP host thinks about its sources relative to its own clock, not relative to the time on the metrics server.
Future plans
My intention is to add two or three more NTP implementations to TLNTC, and have an instance of each implementation on each bare metal server to allow me to measure (and hopefully compensate for) the idiosyncracies of individual systems.
I'll also be adding a new stratum 1 server as soon as the GPS board I have on order arrives. It will be situated at the opposite end of the house, facing the Eastern sky instead of the West, so it should get a slightly different set of satellites.
I plan on enabling AES MAC authentication between the stratum 1 servers and their clients, because I want some experence troubleshooting it. I'll probably also enable NTS on the pool hosts at some point, although how NTS will work with pools is still unclear, and there aren't any standards for it yet.
In my next post I'll describe the configuration needed to get chronyd and ntpd working with the PHC device, and look at how much difference this makes to VM time sync accuracy.
Related posts
- AWS microsecond-accurate time: a second look
- VM timekeeping: Using the PTP Hardware Clock on KVM
- AWS microsecond-accurate time: a first look
- What’s the time, Mister Cloud? An introduction to and experimental comparison of time synchronisation in AWS and Azure, part 1
- What’s the time, Mister Cloud? An introduction to and experimental comparison of time synchronisation in AWS and Azure, part 2