Contents
(Note: Readers who aren't familiar with time sync in public clouds might want to check out my recent series.)
The AWS time sync service
AWS first introduced their NTP-based time service in 2017 and it has been ticking along (pun fully intended) in the background ever since, used by default on almost every preconfigured AMI I've encountered on AWS. There was a blog explaining the service at the time of release, along with documentation on how to configure your Linux and Windows systems to use it. In November 2022, AWS started offering the same service to the public as well.
At release time, mitigating the bugs surrounding the most recent leap second (December 2016) seems to have been at front of mind for AWS, because the announcement had a lot to say about leap smearing. However, they noted in their announcement:
In the future, we will also provide mechanisms for accessing non-leap smeared time.
Of course, we've always been able to access non-leap smeared time from AWS by simply referencing external NTP servers, but in November 2023, AWS announced the release of microsecond-accurate time for their time sync service, making good on their earlier promise. In February 2024 I took the opportunity to test this new feature to see what effects it has on time synchronisation.
Microsecond-accurate time announced
In the announcement blog, the authors state that the improved service "is designed to deliver clock accuracy in the low double-digit microsecond range", compared with the original service's "one millisecond clock accuracy". The target workloads include "financial trading and broadcasting", and the post claims:
With global and reliable microsecond-range clock accuracy, you can now migrate and modernize your most time-sensitive applications in the cloud and retire your burdensome on-premises time infrastructure.
Given that the service is available initially only on R7g instances in Tokyo (ap-northeast-1) and as of March 2024 in Virginia (us-east-1), the "global" claim seems rather inflated, but AWS "will be expanding support additional AWS Regions and EC2 Instance types". Because the "PTP hardware clock is part of the AWS Nitro System", only Nitro-based instances should expect to receive support for it in future. (The contrarian in me would also point out that the on-premises time infrastructure which I use is far from burdensome.)
How it works
The higher accuracy clock service is achieved by exposing a PTP hardware clock (PHC) device to the EC2 instance, very similar to the one provided by Azure (which I covered in my previous post). Whilst the Azure PHC device is a software device provided via the Hyper-V hv_util driver, the AWS PHC device is provided by the Elastic Network Adaptor (ENA), Amazon's NIC driver.
The AWS time sync service documentation has been updated to include the PHC device, and as usual with AWS, it's written to a high standard. The documentation covers setup of chronyd (which natively supports PHC reference clocks) and explains the important issues to address when configuring it. It's also possible to use these devices with ntpd; I'll cover that in a later post.
Prerequisites
The PTP device is supported by the ena driver starting at version 2.10. My preferred Linux distro, Ubuntu, currently includes a much older version of the driver. I didn't want to mess around with compiling the new version, so I tested the PHC device using Amazon Linux 2023 rather than trying to get it working on Ubuntu. (I've submitted a bug asking for the ena driver to be updated.)
The PTP device is not enabled by default and must be configured by loading the driver with an option to enable it. I did this by adding the following to a file in /etc/modprobe.d and rebooting:
options ena phc_enable=1
Hopefully this will be simplified by a future version of the driver enabling the PHC by default.
Chrony configuration
Amazon's recommended chrony configuration snippet for enabling the PHC device is:
refclock PHC /dev/ptp0 poll 0 delay 0.000010 prefer
This instructs chrony to use /dev/ptp0 as a PHC reference clock, polling it once every second, and to assume a delay of 10 microseconds in calculations, regardless of how long it actually takes to read from the PHC device. The reason the delay option is important is that because the PHC device can be read very quickly (about 30 nanoseconds was the lowest value I saw), and without it chronyd will report a misleadingly low value for its root delay and dispersion.
Amazon provides a sysfs device file /sys/devices/pci0000:00/0000:00:05.0/phc_error_bound as part of the ENA driver, from which the clock error bound can be read. The clock error bound is defined in the announcement as the residual adjustment to be applied to the system clock, plus the root dispersion, plus half of the root delay. It ranged between 23.752 and 51.907 microseconds in a brief sample I took. It appears to be updated approximately every second by the driver.
The hypervisor network endpoint (fd00:ec2::123) settled for me on approximately 150-200 microseconds for a round trip. If I bumped the PHC device up to a similar delay, it was still preferred over the network endpoint, presumably due to the lower overhead in reading the device.
Measurements
I gathered data on a single r7g.medium instance (2 ARM64 vCPU cores, 8 GB RAM) over the period of a couple of days. I enabled NTPmon, my NTP monitoring utility, to send data to my InfluxDB metrics store via telegraf, and gathered both system and NTP-specific metrics. The instance was running on an IPv6-only network, although this should be largely immaterial to the results.
A Grafana snapshot is available for those who'd like to play interactively with the data I gathered.
The chrony configuration used mostly the defaults for Amazon Linux 2023, with the following initial peer and reference clock settings:
pool 2.pool.ntp.org iburst # the IPv6-only pool pool fd00:ec2::123 iburst # the AWS hypervisor network endpoint pool ntp.libertysys.com.au iburst # my public NTP servers (in Australia) refclock PHC /dev/ptp0 poll 0 delay 0.000076 # the AWS hypervisor PHC device
I chose not to use the prefer keyword for the refclock or the hypervisor network endpoint, but insted let chrony pick its best sources.
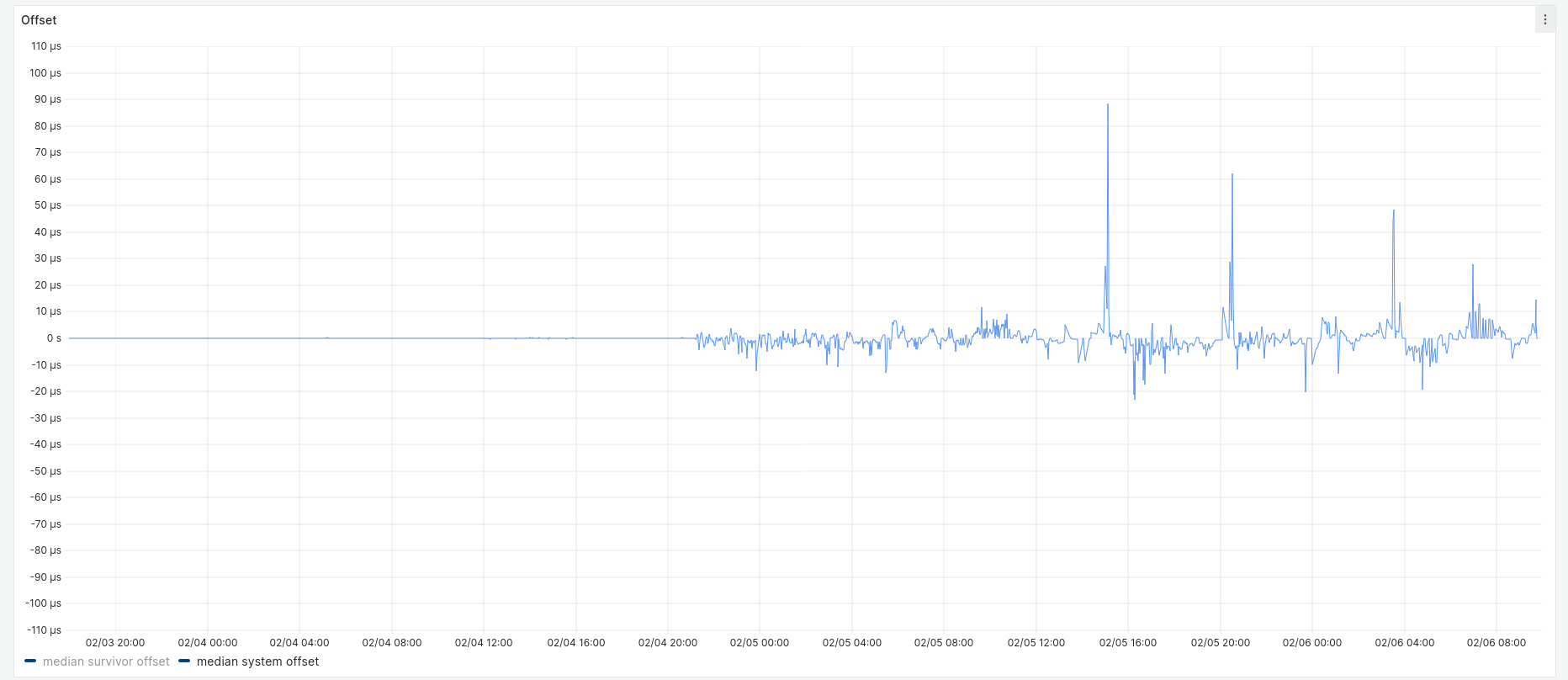
Running this for about 24 hours resulted in the following data for system offset:
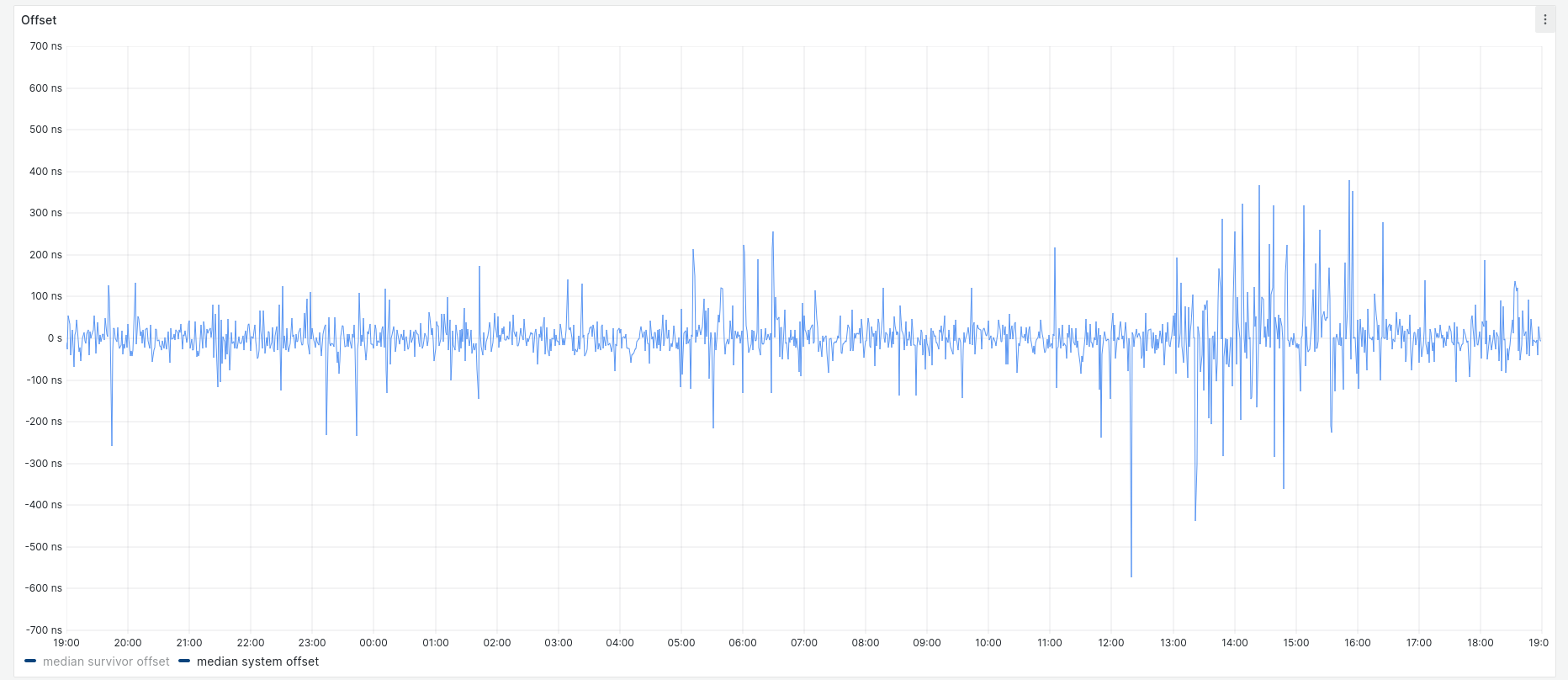
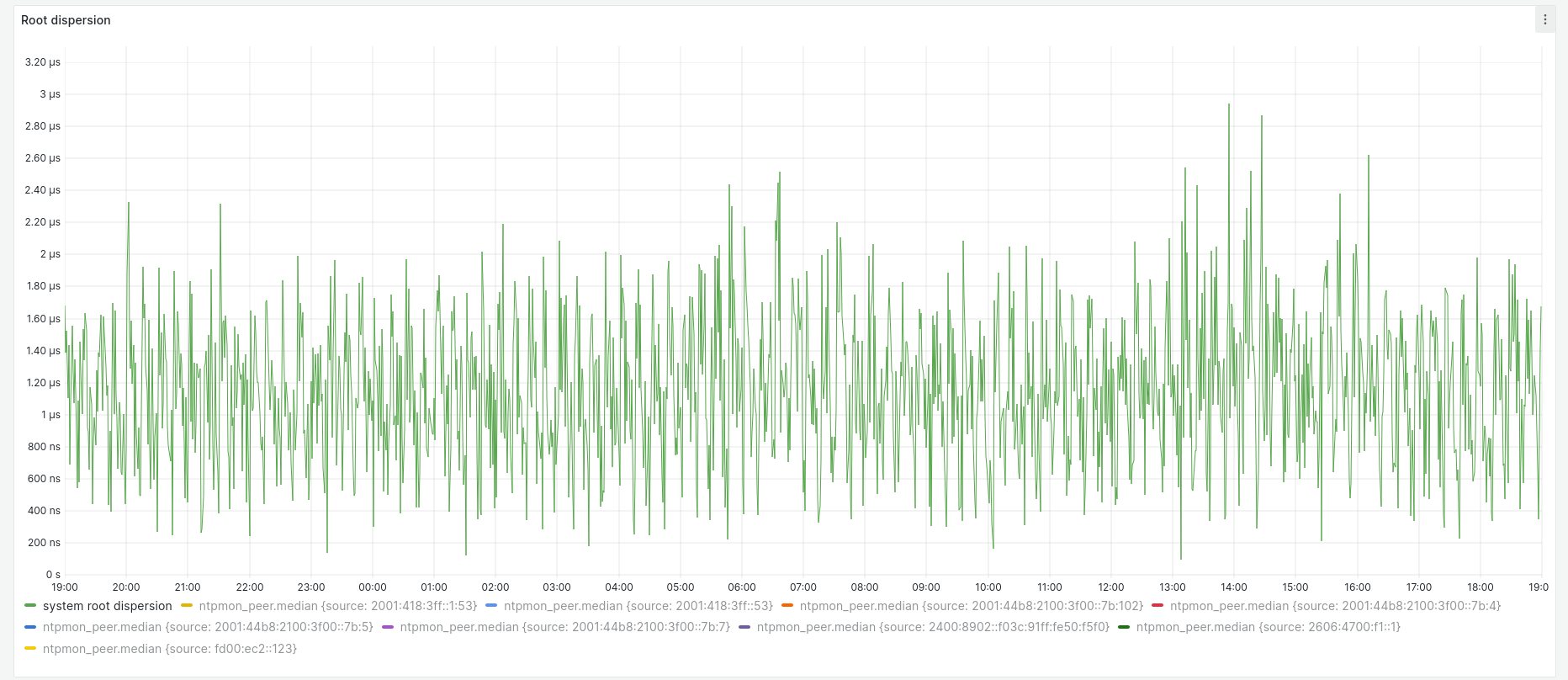
Although the key says median, this and the following graphs actually show every data point collected. All samples fell between +400 ns and -600 ns. Over the same time the root dispersion had a maximum of approximately 3 µs:
After the first 24 hours, I disabled the PHC and restarted chrony. Here are the corresponding system offset and root dispersion graphs:
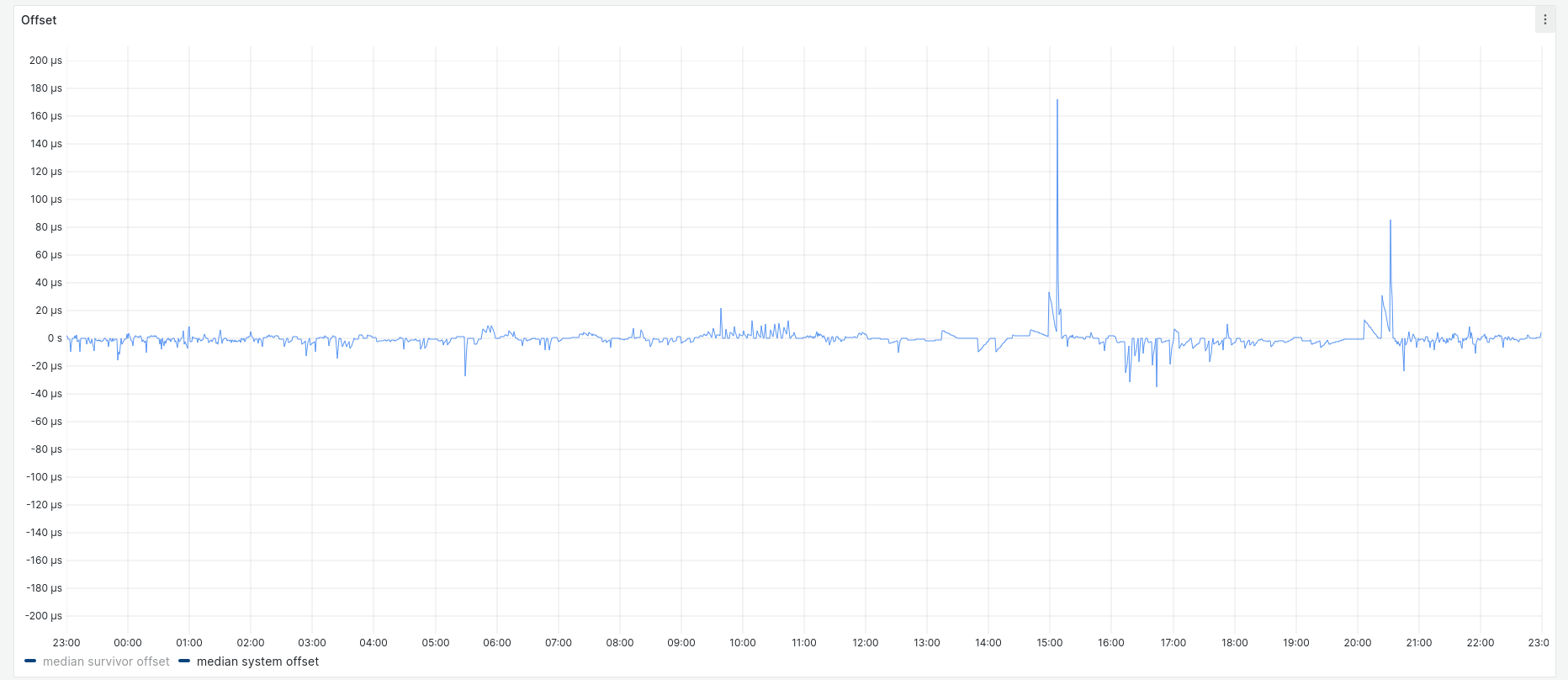
Most system offset samples fell within ± 20 µs, with outliers up to 180 µs.
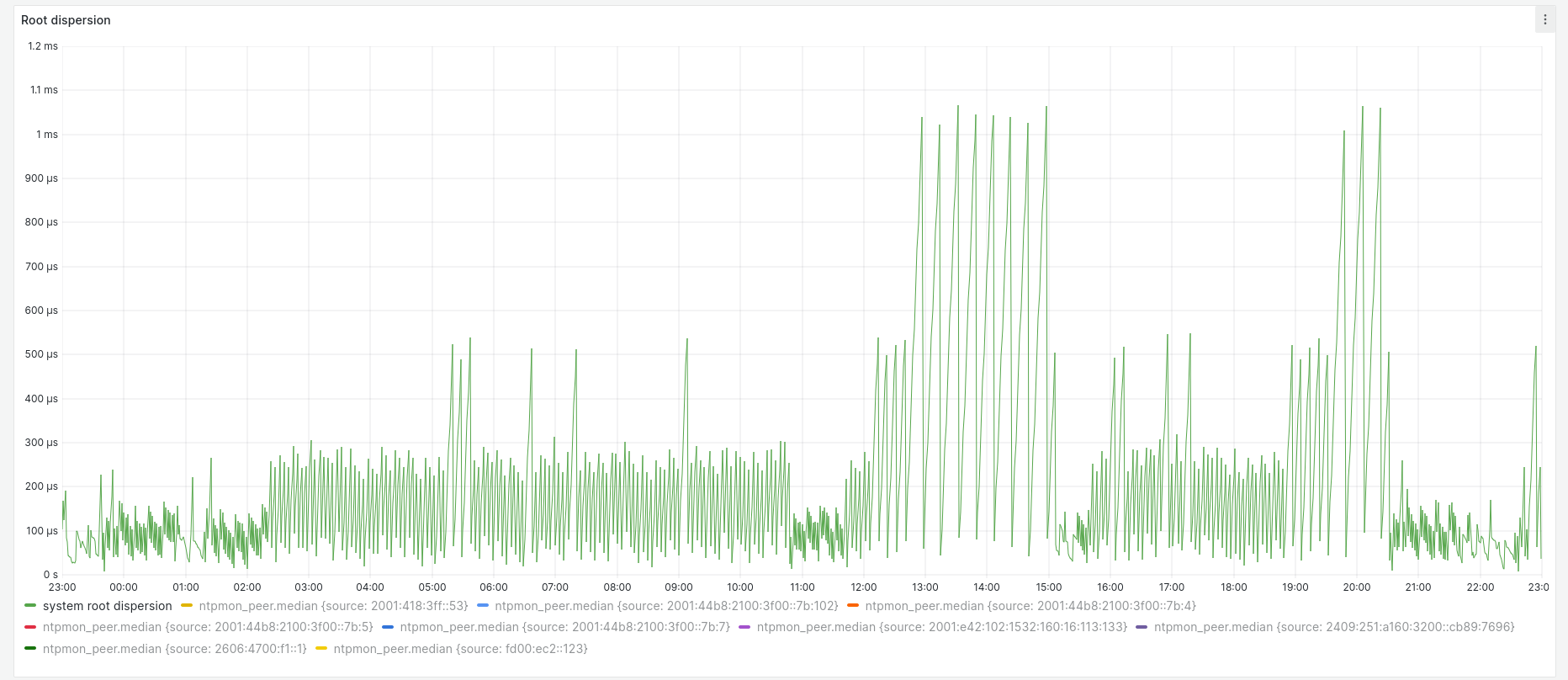
Root dispersion varied a great deal more with the PHC disabled, with peaks between approximately 150 µs and 1.1 milliseconds.
Here's the system offset showing both periods side by side for scale:
and the root dispersion:
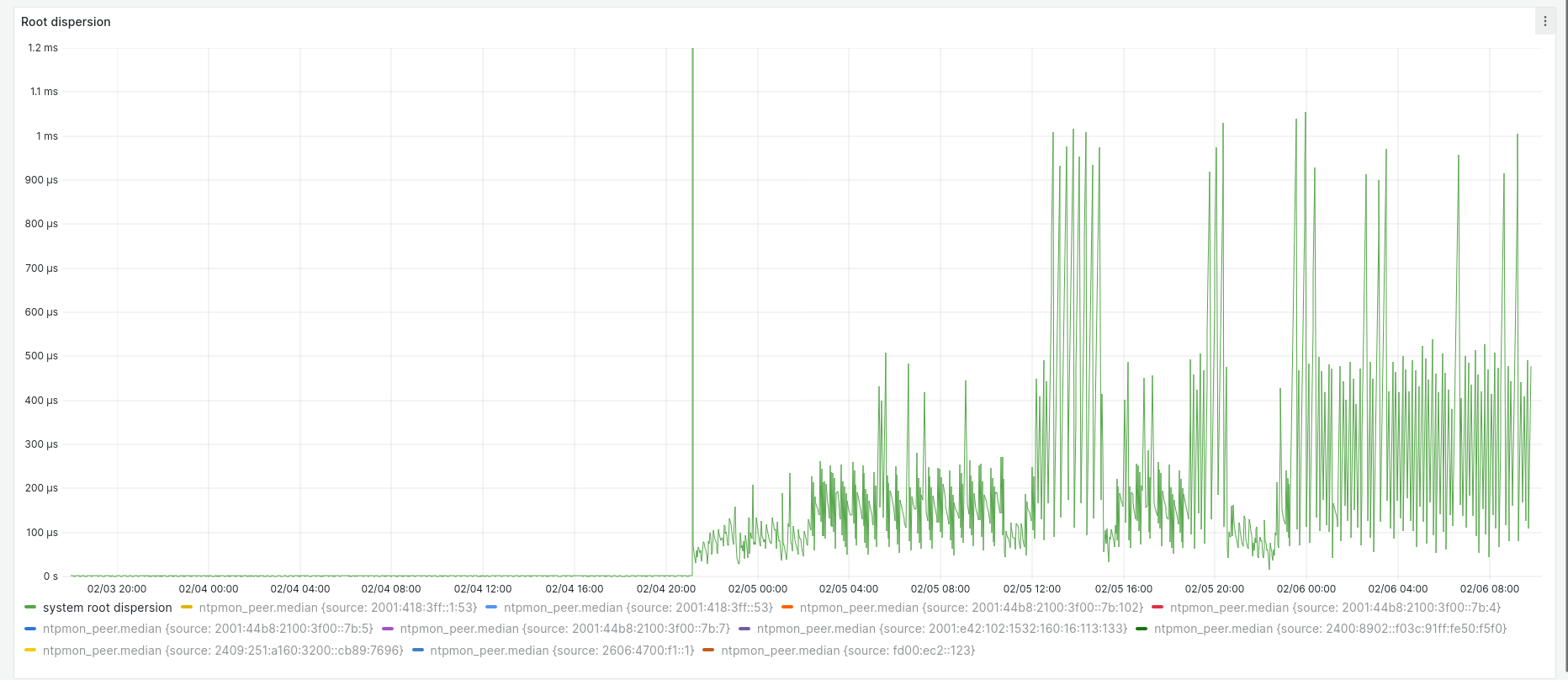
The large spike in root dispersion in the middle marks when chrony was restarted. I've clipped the graph in order to show the two distinct periods clearly; the spike is actually way off the graph at 500 ms.
Conclusion
The measurements seem quite definitive: use of the PHC device with chrony dramatically improves offset (how closely the instance tracks its hypervisor) and root dispersion (the estimated maximum error accumulated from the stratum 0 sources). If offset is used as the metric, the AWS time sync team have beaten their goals by two orders of magnitude.
In upcoming posts I'm going to explore this area further, including configuration walkthroughs for chronyd and ntpd.
Afterthought
At its initial release, the time sync service was described as being backed by "a fleet of redundant satellite-connected and atomic reference clocks", but the November 2023 and March 2024 announcements merely state that it is "GPS-disciplined". I'm not sure whether AWS just reduced the amount of detail for simplicity's sake, or if it means that they have retired their on-premises atomic clock infrastructure (presumably because it was burdensome? 😛).
Related posts
- AWS microsecond-accurate time: a second look
- What’s the time, Mister Cloud? An introduction to and experimental comparison of time synchronisation in AWS and Azure, part 1
- What’s the time, Mister Cloud? An introduction to and experimental comparison of time synchronisation in AWS and Azure, part 2
- What’s the time, Mister Cloud? An introduction to and experimental comparison of time synchronisation in AWS and Azure, part 3
- VM timekeeping: Using the PTP Hardware Clock on KVM